
what is rocksdb
RocksDB is a storage engine with key/value interface, where keys and values are arbitrary byte streams, which means we could use rocksdb to persist our data in memory at ease.
a sample from official simple_example.cc
| |
core concepts
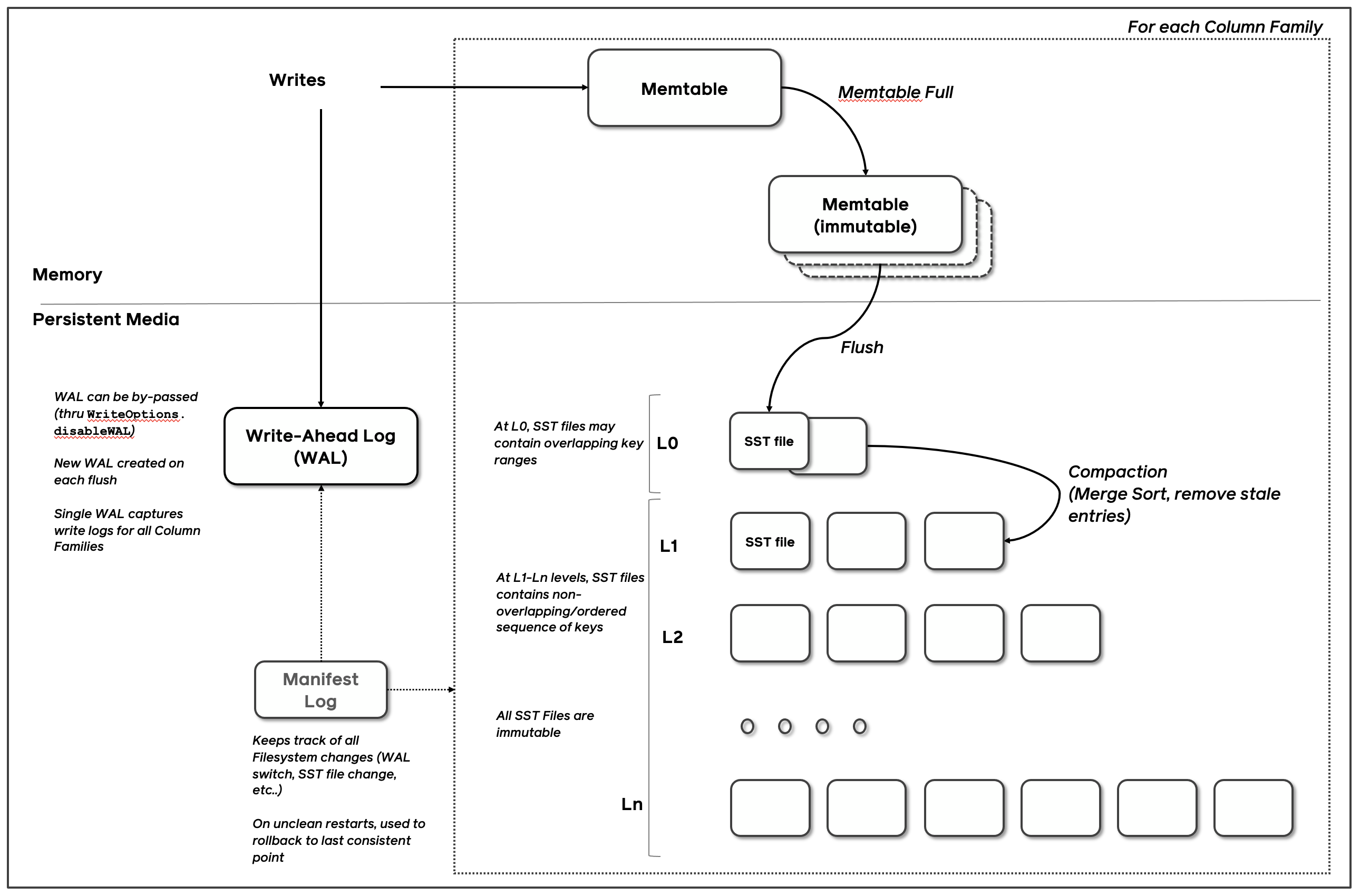
The fundamental components of RocksDB are the MemTable, SSTable, and Write-Ahead Log (WAL). Whenever data is written to RocksDB, it’s added to an in-memory write buffer called the MemTable, and it also supports configurable synchronous logging to the Write-Ahead Log (WAL) on disk. The WAL is primarily used for data durability and crash recovery in case of system failures. The MemTable is by default implemented using a Skip List, which allows it to keep data ordered with insertion and search costs of O(log n).
- mem-table & SSTables
- WAL
- compaction
signature work flow
flowchart TD
WO[Write Operation]
RO[Read Operation]
WAL[Write-Ahead Log]
AMT[Active MemTable<br>Mutable]
IMM[Immutable MemTables]
L0["Level 0<br>Multiple SST Files<br>(Files sorted internally,<br>may overlap in key ranges)"]
L1[Level 1<br>Ordered, No Overlaps]
L2[Level 2<br>10x size of L1]
LN[Level N]
WO --> WAL
WO --> AMT
IMM -- Flush Job / Disk --> L0
L0 -- Compaction --> L1
L1 -- Compaction --> L2
L2 -- Compaction --> LN
RO --> AMT
RO --> IMM
RO --> L0
RO --> L1
RO --> L2
RO --> LN
AMT -- Memory --> IMM
AMT -- Flush --> L0
write path
- (active) memtable
- append WAL (restart, restore)
- once the active memtable becomse full, it is marked as immutable and a new active memtable is created, and the immutable ones are queued for flushing to disk
- immutable memtables are flushed to disk as one or more level 0 SST files (each level 0 file is sorted internally, but key ranges may overlap with other level-0 files)
- possible compaction if the number of SST files reach a certain threshold (4 by default)
read path
- Search the active memtable.
- Search immutable memtables.
- Search all SST files on L0 starting from the most recently flushed.
- For L1 and below, find a single SST file that may contain the key and search the file.
pondering problems
why compaction is a must
Because LSM Trees convert all data modification operations into append-only writes: an insert writes a new data entry, an update writes a modified entry, and a delete writes a tombstone marker—reading data, if not found in memory, requires searching through SSTable files starting from Layer 0. If there are many duplicate entries, this can lead to read amplification. Therefore, Compaction operations are used to merge data in lower layers and clean up marked-for-deletion data, thereby reducing the impact of amplification factors.
three kinds of aimpilication:
- space – occupy more space than the raw data (append-only strategy)
- read – worst O(n)
- write – worst trigger multiple layer (flush) compaction
compaction strategies (ClaudeAI )
RocksDB offers multiple compaction strategies to optimize for different workloads and access patterns. The choice of compaction strategy significantly impacts the three amplification factors (space, read, write).
Leveled Compaction (Default)
The most commonly used strategy that maintains strict ordering across levels:
| |
Characteristics:
- Each level (except L0) has non-overlapping key ranges
- Each level is ~10x larger than the previous level
- L0 → L1 compaction merges overlapping files
- L1+ compactions merge one file from upper level with overlapping files from lower level
Trade-offs:
- ✅ Read amplification: O(log N) - only need to check one file per level
- ✅ Space amplification: ~1.11x - minimal extra space
- ❌ Write amplification: High - data gets rewritten multiple times as it moves down levels
Best for: Read-heavy workloads, range queries, when storage space is premium
Universal Compaction
Designed to minimize write amplification by keeping fewer levels:
| |
Characteristics:
- Files within each level are sorted by age (newest first)
- Compaction triggers based on size ratios and file count
- May compact entire levels at once
- More flexible triggering conditions
Trade-offs:
- ✅ Write amplification: Lower - less frequent major compactions
- ✅ Space amplification: Better for write-heavy workloads
- ❌ Read amplification: Higher - may need to check multiple files per level
- ❌ Temporary space: Requires more temporary disk space during compaction
Best for: Write-heavy workloads, when write performance is critical
FIFO Compaction
Simplest strategy that treats the database as a circular buffer:
| |
Characteristics:
- Only keeps data within a time window or size limit
- Deletes entire SST files when limits are exceeded
- No actual compaction/merging occurs
- Data automatically expires
Trade-offs:
- ✅ Write amplification: Minimal - no data rewriting
- ✅ Space amplification: Predictable - bounded by configured limits
- ❌ Data retention: Limited - old data gets deleted
- ❌ Read performance: May degrade over time
Best for: Time-series data, caching use cases, when data has natural expiration
Configuration Examples
| |
Choosing the Right Strategy
| Workload Pattern | Recommended Strategy | Reasoning |
|---|---|---|
| Read-heavy OLTP | Leveled | Low read amplification, good for point lookups |
| Write-heavy logging | Universal or FIFO | Lower write amplification |
| Time-series data | FIFO | Natural data expiration, minimal overhead |
| Mixed workload | Leveled (tuned) | Balance between read/write performance |
| Cache/temporary data | FIFO | Automatic cleanup, predictable space usage |
The key is to understand your access patterns and optimize for the most critical amplification factor in your use case.
references
- https://deepwiki.com/facebook/rocksdb/1-overview
- https://github.com/facebook/rocksdb/wiki/RocksDB-Overview
- https://www.luozhiyun.com/archives/842
- https://artem.krylysov.com/blog/2023/04/19/how-rocksdb-works/
- https://www.scylladb.com/2018/01/17/compaction-series-space-amplification/
- https://www.scylladb.com/2018/01/31/compaction-series-leveled-compaction/