
First of all, I have to admit that I didn’t know raft quite well, and this article will only stand as a learning record, thanks for your understanding.
Raft is a consensus algorithm for managing a replicated log.
Consensus algorithms allow a collection of machines to work as a coherent group that can survive the failures of some of its members.
Novel features over Oki and Liskov’s Viewstamped Replication
Strong leader: Raft uses a stronger form of leadership than other consensus algorithmsLeader election: Raft uses randomized timers to elect leaders (to avoid election conflict)Membership changes: Raft’s mechanism for changing the set of servers in the cluster uses a new joint consensus approach where the majorities of two different configurations overlap during transitions
Replicated state machine
Consensus algorithms typically arise in the context of replicated state machine. Replicated state machines are used to solve a variety of fault tolerance problems in distributed systems.
Replicated state machines are typically implemented using a replicated log. Each server stores a log containing a series of commands, which its state machine executes in order. Each log contains the same commands in the same order, so each state machine processes the same sequence of commands. Since the state machines are deterministic, each computes the same state and the same sequence of outputs.
Consensus algorithms properties
- ensure
safety(never returning an incorrect result) under all non-Byzantine conditions, including network delays, partitions, packet loss, dulication and reordering - are fully functional (available) as long as any majority of the servers are operational and can communicate with each other and with clients
- do not depend on timing to ensure the consistency of the logs: faulty clocks and extreme message delays can, at worst, cause availability problems
- in the most common case, a command can complete as soon as a majority of the cluster has responded to a single round of RPC; a minority of slow servers need not impact overall system performance
Problems of Paxos
- exceptionally difficult to understand
- no good foundation for building practical implementations
The Raft Consensus Algorithm
Raft implements consensus by first electing a distinguished leader, then giving the leader complete responsibility for managing the replicated log. The leader accepts log entries from clients, replicates them on other servers, and tell servers when it is safe to apply on log entries to their state machines.
Three sub-sections
Leader election: a new leader must be chosen when an existing leader failsLog replication: the leader must accept log entries from clients and replicate them across the cluster, forcing the other logs to agree with its ownSafety: the key safety property for Raft is the State Machine Safety
Raft gurantees
Election Safety: at most one leader can be elected in a given termLeader Append-Only: a leader never overwrites or deletes entries in its log; it only appends new entriesLog Matching: if two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given indexLeader Completeness: if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered termsState Machine Safety: if any server has applied a particular log entry to its state machine, then no other server may apply a different command for the same log index
Raft Node State
persistent on all servers:
- currentTerm – latest term server has seen
- votedFor – candidateId that received vote in current term
- log[] – log entries
volatile on all servers:
- commitIndex – index of highest log entry known to be committed
- lastApplied – index of highest log entry applied to state machine
volatile on leader:
- nexIndex[] – index of the next log entry to send to each server
- matchIndex[] – index of highest log entry known to be replicated on server
Raft Basics
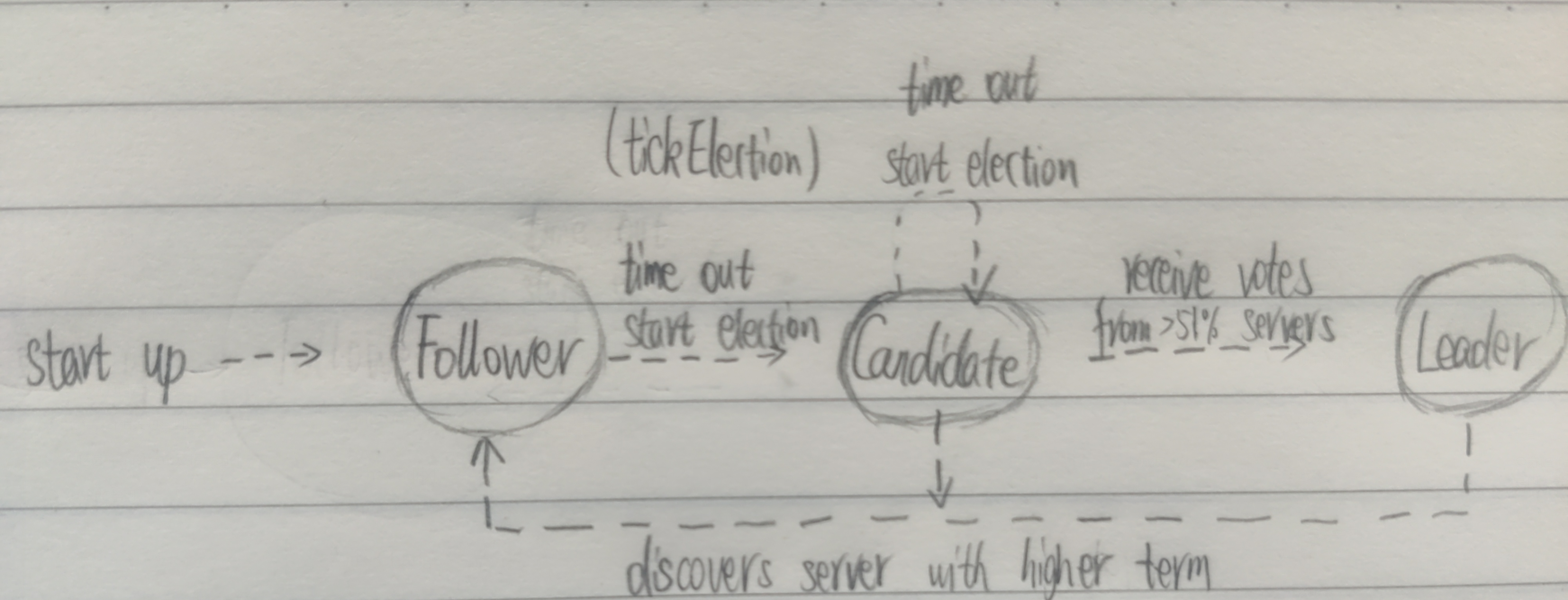
A Raft cluster contains several servers; five is a typical number, which allows the system to tolerate two failures. At any given time each server is in one of three state: leader, follower or candidate. In normal operation there is exactly one leader and all of the other servers are followers. Followers are passive: they issue no requests on their own but simply respond to requests from leaders and candidates. The leader handles all client requests.
Leader Election
Raft uses a heartbeat mechanism to trigger leader election. When servers start up, they begin as follower. A server remains in follower state as long as it receives valid RPCs from a leader or a candidate. Leaders send periodic heartbeats (AppendEntries RPCs that carry no log entries) to all followers in order to maintain their authority.
If a follower receives no communication over a period of time called the election timeout, then it assumes there is no viable leader and begins an election to choose a new leader.
Log Replication
Each client request contains a command to be executed by the replicated state machines. The leader appends the command to its log as a new entry, then issues AppendEntries RPCs in parallel to each of the other servers to replicate the entry. When the entry has been safely replicated, the leader applies the entry to its state machine and returns the result of that execution to the client. If followers crash or run slowly, or if network packets are lost, the leader retries AppendEntries Rpcs indefinitely (even after it has respond to the client) until all followers eventually store all log entry.
Safety
Election Restriction
In any leader-based consensus algorithm, the leader must eventually store all of the committed log entries.
Raft uses the voting process to prevent a candidate from winning an election unless its log contains all committed entries. A candidate must contact a majority of the cluster in order to be elected, which means that every committed entry must be present in at least one of those servers.
Follower and candidate crashes
If a follower or candidate crashes, then future RequestVote and AppendEntries RPCs sent to it will fail. Raft handles these failures by retrying indefinitely; if the crashed server restarts, then the RPC will complete successfully. If a server crashes after completing an RPC but before responding, then it will receive the same RPC again after it restarts. Raft RPCs are idempotent, so this causes no harm.
Timing and availability
Leader election is the aspect of Raft where timing is most critical. Raft will be able to elect and maintain a steady leader as long as the system satifies the following timing requirement:
$$broadCastTime « electionTimeout « MTBF$$
- broadCastTime is the average time it takes a server to send RPCs in parallel to every server in the cluster and receive their responses
- MTBF is the average time between failures for a single server
Log Compaction
Snapshotting is the simplest approach to compaction. In snapshotting, the entire current system state is written to a snapshot on stable storage, then the entire log up to that point is discarded.
Client interaction
Client of Raft send all of their requests to the leader. When a client first starts up, it connects to a randomly-chosen server. If the client’s first choice is not the leader, that server will reject the client’s request and supply information about the most recent leader it has heard from. If the leader crashes, client requests will timout; clients then try again with randomly-chosen servers.
Not a Conclusion
For further understanding, check the Raft Visualization.